Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, Jianqiao Lu, Hugues de Saxcé, Bolton Bailey, Chendong Song, Chenjun Xiao, Dehao Zhang, Ebony Zhang, Frederick Pu, Han Zhu, Jiawei Liu, Jonas Bayer, Julien Michel, Longhui Yu, Léo Dreyfus-Schmidt, Lewis Tunstall, Luigi Pagani, Moreira Machado, Pauline Bourigault, Ran Wang, Stanislas Polu, Thibaut Barroyer, Wen-Ding Li, Yazhe Niu, Yann Fleureau, Yangyang Hu, Zhouliang Yu, Zihan Wang, Zhilin Yang, Zhengying Liu, Jia Li
cs.AI
Apr 15, 2025 · v1
TL;DR
Kimina-Prover is an RL-trained LLM generating Lean 4 proofs, setting a new state-of-the-art on the miniF2F benchmark.
Abstract
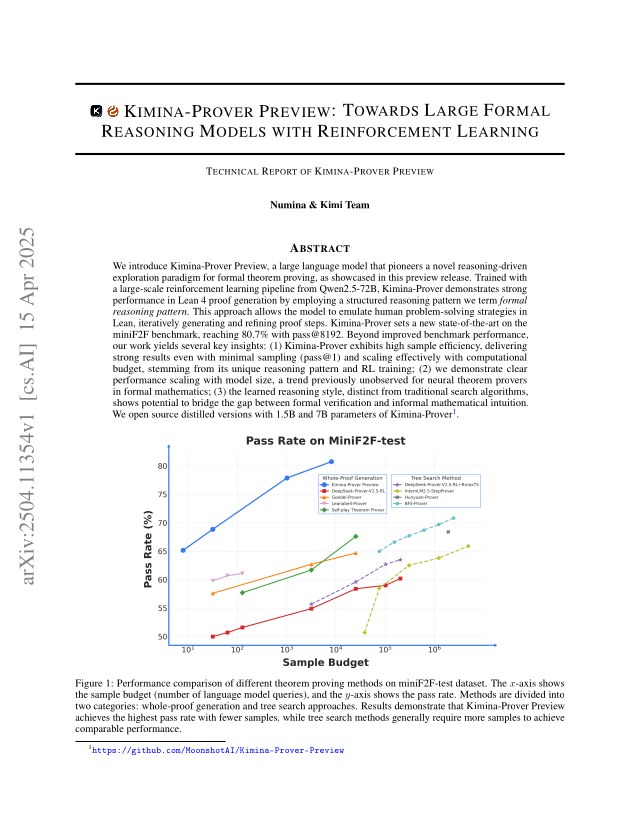
We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
Problem
Neural theorem provers for Lean 4 have relied on step-level tactic generation coupled with tree search, which limits reasoning depth and does not scale well with model size.
Approach
Kimina-Prover is trained from Qwen2.5-72B using large-scale reinforcement learning with a formal reasoning pattern that emulates human problem-solving in Lean: the model iteratively generates and refines proof steps within a structured reasoning trace. An autoformalization pipeline provides diverse training problems by translating natural-language statements into valid Lean 4 code.
Results
Kimina-Prover achieves 80.7% on miniF2F with pass@8192, setting a new state-of-the-art. The model demonstrates clear performance scaling with model size (a trend previously unobserved for neural theorem provers) and high sample efficiency even at pass@1.