DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition
Z. Z. Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, Z. F. Wu, Zhibin Gou, Shirong Ma, Hongxuan Tang, Yuxuan Liu, Wenjun Gao, Daya Guo, Chong Ruan
cs.CL
Apr 30, 2025 · v1
TL;DR
DeepSeek-Prover-V2 is an LLM for formal theorem proving in Lean 4, trained via RL with recursive subgoal decomposition.
Abstract
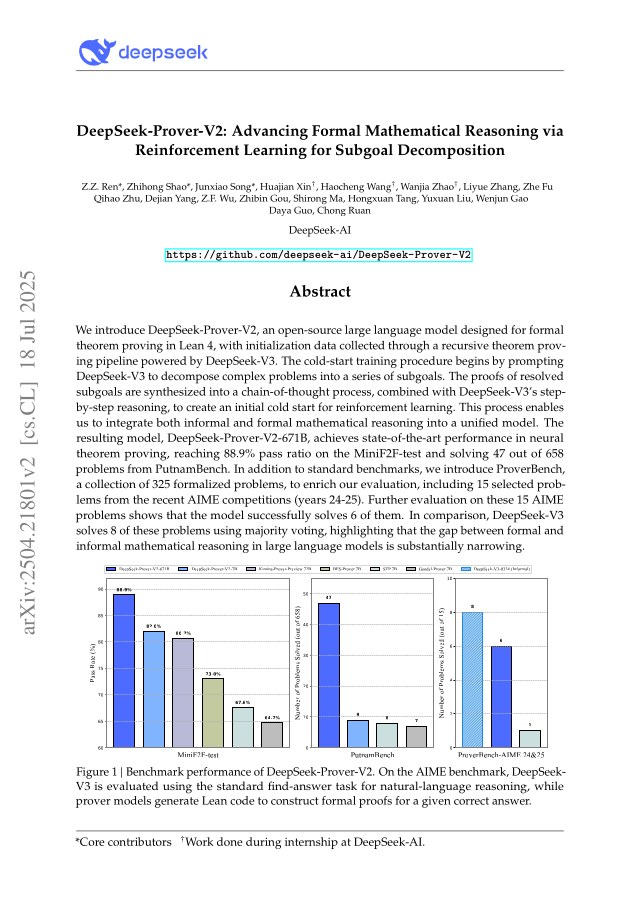
We introduce DeepSeek-Prover-V2, an open-source large language model designed for formal theorem proving in Lean 4, with initialization data collected through a recursive theorem proving pipeline powered by DeepSeek-V3. The cold-start training procedure begins by prompting DeepSeek-V3 to decompose complex problems into a series of subgoals. The proofs of resolved subgoals are synthesized into a chain-of-thought process, combined with DeepSeek-V3's step-by-step reasoning, to create an initial cold start for reinforcement learning. This process enables us to integrate both informal and formal mathematical reasoning into a unified model. The resulting model, DeepSeek-Prover-V2-671B, achieves state-of-the-art performance in neural theorem proving, reaching 88.9% pass ratio on the MiniF2F-test and solving 49 out of 658 problems from PutnamBench. In addition to standard benchmarks, we introduce ProverBench, a collection of 325 formalized problems, to enrich our evaluation, including 15 selected problems from the recent AIME competitions (years 24-25). Further evaluation on these 15 AIME problems shows that the model successfully solves 6 of them. In comparison, DeepSeek-V3 solves 8 of these problems using majority voting, highlighting that the gap between formal and informal mathematical reasoning in large language models is substantially narrowing.
Problem
Formal theorem proving in Lean 4 requires both informal mathematical reasoning to identify proof strategies and formal tactic-level generation to produce verified proofs. Combining these capabilities in a single system at scale remained an open challenge.
Approach
DeepSeek-Prover-V2 uses a recursive theorem proving pipeline powered by DeepSeek-V3 for cold-start data collection. Complex problems are decomposed into subgoals by prompting DeepSeek-V3 to generate natural-language proof sketches while simultaneously formalizing them into Lean statements with sorry placeholders. A 7B prover model recursively solves decomposed subgoals. The synthesized proofs create chain-of-thought training data that combines informal and formal reasoning, used as a cold start for reinforcement learning.
Results
DeepSeek-Prover-V2 achieves 88.9% pass rate on miniF2F-test with a budget of 8192 samples, reaching 100% on MATH Algebra and 93.3% on AIME problems. The 671B model uses chain-of-thought reasoning with average 6752 output tokens per proof. On PutnamBench it sets a new state-of-the-art.
| Category | Pass Rate |
|---|
| MATH Algebra | 70/70 = 100% |
| MATH Number Theory | 58/60 = 96.7% |
| AIME | 14/15 = 93.3% |
| AMC | 35/45 = 77.8% |
| IMO | 10/20 = 50.0% |
| Overall | 217/244 = 88.9% |
DeepSeek-Prover-V2 miniF2F-test results by category (Pass@8192)