Leanabell-Prover-V2: Verifier-integrated Reasoning for Formal Theorem Proving via Reinforcement Learning
Xingguang Ji, Yahui Liu, Qi Wang, Jingyuan Zhang, Yang Yue, Rui Shi, Chenxi Sun, Fuzheng Zhang, Guorui Zhou, Kun Gai
cs.AI
Jul 11, 2025 · v1
TL;DR
Post-trains a 7B LLM with reinforcement learning using Lean 4 verifier feedback to produce formal proofs.
Abstract
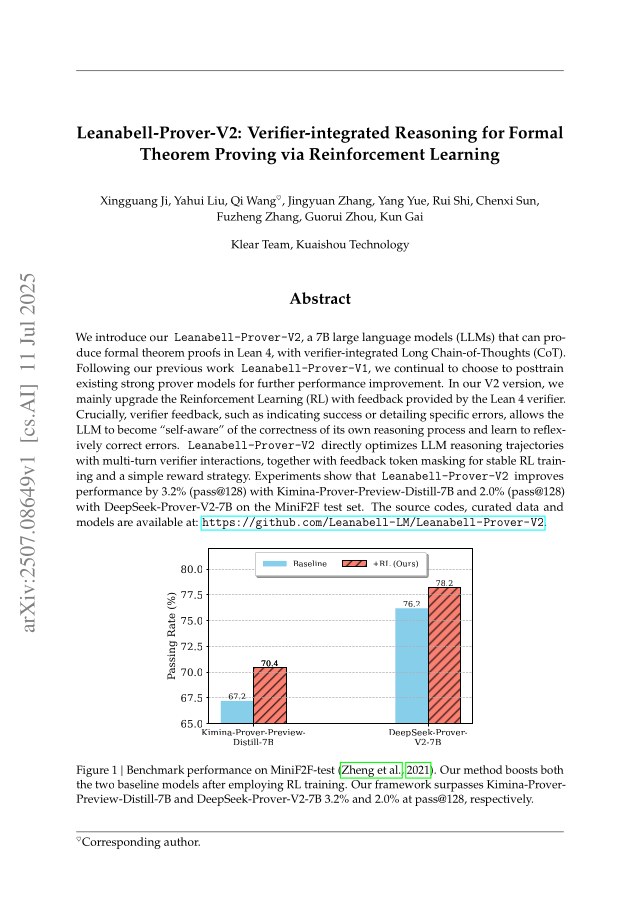
We introduce our Leanabell-Prover-V2, a 7B large language models (LLMs) that can produce formal theorem proofs in Lean 4, with verifier-integrated Long Chain-of-Thoughts (CoT). Following our previous work Leanabell-Prover-V1, we continual to choose to posttrain existing strong prover models for further performance improvement. In our V2 version, we mainly upgrade the Reinforcement Learning (RL) with feedback provided by the Lean 4 verifier. Crucially, verifier feedback, such as indicating success or detailing specific errors, allows the LLM to become ``self-aware'' of the correctness of its own reasoning process and learn to reflexively correct errors. Leanabell-Prover-V2 directly optimizes LLM reasoning trajectories with multi-turn verifier interactions, together with feedback token masking for stable RL training and a simple reward strategy. Experiments show that Leanabell-Prover-V2 improves performance by 3.2% (pass@128) with Kimina-Prover-Preview-Distill-7B and 2.0% (pass@128) with DeepSeek-Prover-V2-7B on the MiniF2F test set. The source codes, curated data and models are available at:
https://github.com/Leanabell-LM/Leanabell-Prover-V2.
Problem
Large language models for formal theorem proving in Lean 4 lack self-awareness of proof correctness during generation, limiting their ability to recover from errors in long chain-of-thought reasoning.
Approach
Leanabell-Prover-V2 post-trains existing strong prover models (7B parameters) using reinforcement learning with feedback from the Lean 4 verifier. The verifier provides success/error signals that are integrated into long chain-of-thought generation, enabling the model to detect and correct its own proof attempts during generation.
Results
The method surpasses Kimina-Prover-Preview-Distill-7B and DeepSeek-Prover-V2-7B by 3.2% and 2.0% respectively at pass@128 on MiniF2F-test. The RL training with verifier feedback improves both baseline models it is applied to.