Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Luoxin Chen, Jinming Gu, Liankai Huang, Wenhao Huang, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Kaijing Ma, Cheng Ren, Jiawei Shen, Wenlei Shi, Tong Sun, He Sun, Jiahui Wang, Siran Wang, Zhihong Wang, Chenrui Wei, Shufa Wei, Yonghui Wu, Yuchen Wu, Yihang Xia, Huajian Xin, Fan Yang, Huaiyuan Ying, Hongyi Yuan, Zheng Yuan, Tianyang Zhan, Chi Zhang, Yue Zhang, Ge Zhang, Tianyun Zhao, Jianqiu Zhao, Yichi Zhou, Thomas Hanwen Zhu
cs.AI
Jul 31, 2025 · v1
TL;DR
Seed-Prover is a whole-proof LLM that iteratively refines Lean proofs using Lean feedback, proved lemmas, and self-summarization.
Abstract
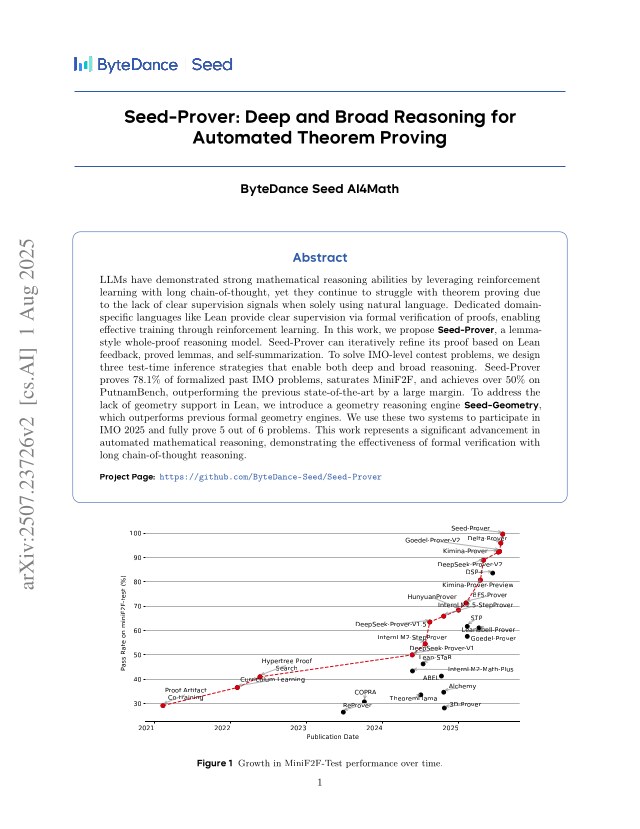
LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
Problem
LLMs struggle with theorem proving due to the lack of clear supervision signals in natural language. Existing automated provers have not achieved high success rates on IMO-level problems or broad competition benchmarks.
Approach
The authors propose Seed-Prover, a lemma-style whole-proof reasoning model that iteratively refines proofs based on Lean feedback, proved lemmas, and self-summarization. Training uses reinforcement learning with formal verification as the reward signal. Three test-time inference strategies enable both deep and broad reasoning. A companion system, Seed-Geometry, provides geometry reasoning capabilities absent in standard Lean.
Results
Seed-Prover proves 78.1% of formalized past IMO problems, saturates MiniF2F, and achieves over 50% on PutnamBench. The system was used in IMO 2025 and fully proved 5 out of 6 problems. These results outperform the previous state-of-the-art by a large margin.