Applies the Self-Guided Self-Play algorithm to Lean4 formal theorem proving, with a Guide model preventing conjecturer collapse.
Abstract
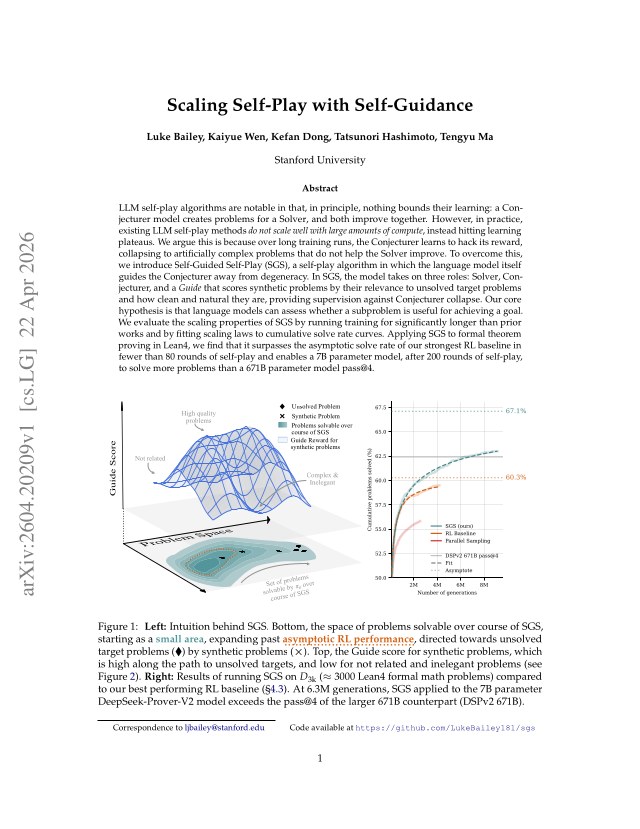
LLM self-play algorithms are notable in that, in principle, nothing bounds their learning: a Conjecturer model creates problems for a Solver, and both improve together. However, in practice, existing LLM self-play methods do not scale well with large amounts of compute, instead hitting learning plateaus. We argue this is because over long training runs, the Conjecturer learns to hack its reward, collapsing to artificially complex problems that do not help the Solver improve. To overcome this, we introduce Self-Guided Self-Play (SGS), a self-play algorithm in which the language model itself guides the Conjecturer away from degeneracy. In SGS, the model takes on three roles: Solver, Conjecturer, and a Guide that scores synthetic problems by their relevance to unsolved target problems and how clean and natural they are, providing supervision against Conjecturer collapse. Our core hypothesis is that language models can assess whether a subproblem is useful for achieving a goal. We evaluate the scaling properties of SGS by running training for significantly longer than prior works and by fitting scaling laws to cumulative solve rate curves. Applying SGS to formal theorem proving in Lean4, we find that it surpasses the asymptotic solve rate of our strongest RL baseline in fewer than 80 rounds of self-play and enables a 7B parameter model, after 200 rounds of self-play, to solve more problems than a 671B parameter model pass@4.
Problem
LLM self-play for theorem proving plateaus because, over long training runs, the Conjecturer hacks its reward by producing artificially complex problems that do not help the Solver.
Approach
Self-Guided Self-Play (SGS) gives one model three roles -- Solver, Conjecturer, and a Guide that scores synthetic problems by relevance to unsolved targets and by how clean and natural they are. Problems are formal math questions in Lean4, providing verifiable rewards.
Figure 1: Left: Intuition behind SGS. Bottom, the space of problems solvable over course of SGS, starting as a small area , expanding past asymptotic RL performance , directed towards unsolved target problems ( \blacklozenge ) by synthetic problems ( \bm{\times} ). Top, the Guide score for synthetic problems, which is high along the path to unsolved targets, and low for not related and inelegant p
Results
On Lean4 theorem proving, SGS surpasses the asymptotic solve rate of the strongest RL baseline in under 80 rounds, and after 200 rounds a 7B model solves more problems than a 671B model at pass@4. Without the Guide, over 80% of generated problems degenerate into disjunctive conclusions.
Figure 12: SGS and STP (Dong & Ma, 2025 ) performance on D_{\text{3k}} . We see that SGS has superior scaling, with a crossover happening at around 1M generations.